

Smart Alerts for Proactive Care: Using Artificial Intelligence To Give Our Coaches Superpowers



TL;DR:
- Proactive care is an essential part of delivering continuous remote care at scale.
- Systems based on ML algorithms, which involve cross-functional collaboration and experimentation, can make proactive care more effective & efficient.
- We identified 5 key steps to building and improving an effective Proactive Alert Pipeline: (1) determine all engagement opportunities, (2) intelligently prune, (3) prioritize, (4) integrate with EHR, (5) collect feedback from clinical users.
Introduction
As a senior machine learning (ML) engineer on Virta’s applied AI team, my work centers on developing intelligent systems that harness our unique and exponentially growing datastores. Such systems have ML algorithms at their core and can be helpful in just about any area of the business. I currently focus on building systems that enhance our treatment—both for the clinicians providing care and the patients reversing their diabetes.
One of Virta’s competitive advantages is the expertise of our elite coaching staff. Our coaches are on the frontlines of reversing diabetes every single day, bridging the gap between information and implementation by answering questions, providing encouragement, giving feedback (e.g. troubleshooting biomarkers like blood glucose), and personalizing the treatment to meet individual patient needs in a myriad of other ways. We have a very high bar in our coach recruiting process to ensure that patients receive top-notch care. To scale successfully, we must help our amazing coaches meet the needs of our patients by directing their attention to specific patients at the right time.
Our coaches engage with patients in two ways: reactive and proactive care. Reactive care is coach engagement in response to explicit patient requests for support, such as answering patient questions about dietary choices or their recent blood ketone values. Proactive care is coach engagement that isn’t in response to explicit patient requests. For example, reaching out after noticing a lack of blood glucose values recorded, or celebrating an achievement (e.g. medication reduction, diabetes reversal, or weight loss). While reactive care helps meet immediate care needs, it relies on the patient to initiate the conversation. Sometimes patients either aren’t aware they need help, or feel uncomfortable asking for it. By providing proactive care, coaches quickly jump in when issues first arise and provide a steady flow of encouragement to keep motivation high. Our NPS and other survey data confirms that proactive care is one of our differentiators for patients, who repeatedly emphasize how much they love hearing proactive feedback, getting support before they have to ask, and having someone who celebrates their accomplishments.
Proactive care, while arguably underemphasized in US healthcare, is not a new idea. Many hospital systems and health plans have been promoting proactive care such as cancer screenings and case management. If they can spot issues early and tackle health problems before they spiral out of control, they can improve outcomes and prevent costly, more severe health problems. At Virta, we are uniquely positioned to improve proactive care through the tight partnership between the clinical experts on our provider and health coach teams, and technical experts on our engineering, applied AI, and data science teams. Together, we developed AI systems that can comb through de-identified data from thousands of patients (i.e. messages, biomarkers, labs, outcomes), identify those who would benefit from proactive care, and alert coaches accordingly everyday.
As these alerts become even more finely tuned, they give our coaches superpowers by helping them know precisely when to reach out to a specific patient. It would take a coach an inordinate amount of time to sift through all of their patient records and spot potential issues without the help of technology. Generating ML-based proactive alerts can help, but requires solving a Goldilocks problem - we need “just the right amount” of alerts. Too little alerting means we’ll miss patients and they may struggle for too long, making it difficult to course correct. Too much alerting will lead to false positives and means we’ll overload coaches, who’ll be back to sifting through too much information. We built our Proactive Alert Pipeline, described in detail below, to solve this problem.
The goals of our Proactive Alert Pipeline are to:
- Inform coaches of patients who are likely to benefit from proactive outreach.
- Provide information that is action-oriented.
- Optimize alert volume by ensuring patients don’t get overlooked while avoiding coach overload, so that coaches are alerted to the right patients at the right time.
Building the Proactive Alert Pipeline
Proactive Alerts are implemented as a batch-oriented pipeline that ingests patient characteristics and events from our data warehouse and publishes alerts periodically to a backend service that manages a coach’s queue. This queue gets surfaced to coaches in Spark. Spark is our homegrown, continuous remote care platform—like an EHR with built-in remote patient monitoring. While there are many interesting technical pieces and learnings to share on how we designed, implemented, and iterated on the different components in the diagram below, for this post, I’ll mainly focus on the Proactive Alert Pipeline.
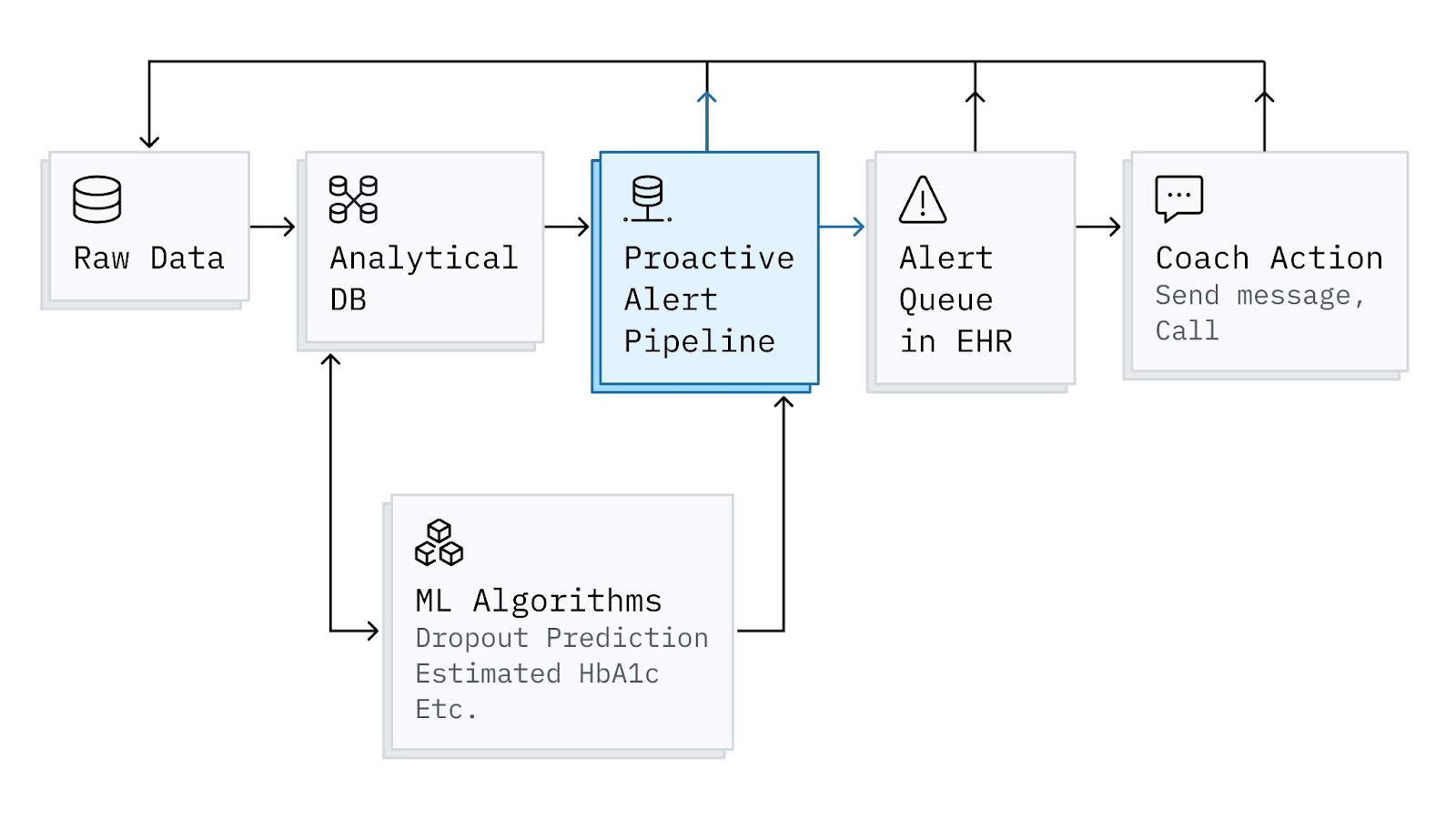
To meet the goals mentioned earlier, we designed the pipeline to run in this sequence:
- Determine all possible patient engagement opportunities and collect actionable context.
- Intelligently prune engagement opportunities.
- Prioritize the remaining engagement opportunities.
- Aggregate, reformat, and add engagement opportunities to the Alert Queue.
- Collect feedback on alert relevance.
1. Determine all possible patient engagement opportunities and collect actionable context.
At the core of the pipeline are the set of “patient engagement opportunities” and their accompanying context, which allows coaches to readily take action on alerts that are surfaced. The engagement opportunity definitions and context are continuously iterated on by a cross-functional team of Virtans including applied AI, operations, design, and product. Together, we determine: the set of engagement opportunities that warrant an alert, what type of information would be useful to provide alongside the alert, and how to extract that information reliably from our datastores. To keep up with changing needs as we grow and evolve our processes and tools, we‘ve added dozens of new engagement opportunities to the start of the pipeline. Of equal importance, we have also modified and removed ones that are no longer useful based on qualitative and quantitative feedback (more on this in section 5 below).
2. Intelligently prune engagement opportunities.
Once a large set of patient engagement opportunities has been generated, there are several “pruning” steps we’ve found useful to intelligently eliminate ones that are less relevant:
- Removing alerts for patients who have recently received an alert for the same or similar engagement opportunities. For example, say we generate a “No Glucose Logs in {X} Days” for a patient on Monday, and a coach sends a message to the patient based on the alert, but still no log occurred by Tuesday. It’s not useful to generate another “No Glucose Logs in {X+1} Days” alert, because it’s generally more effective to wait a few days rather than send a quick follow up.
- Removing alerts for specific engagement opportunities. For example, this is particularly useful when running A/B type tests on the pipeline.
- Removing excessive engagement opportunities for a given patient. For example, we found that after a certain point, even if a patient qualifies for many engagement opportunities, surfacing all of them has diminishing value and coaches prefer to have a smaller number to focus on at a given time.
3. Prioritize the remaining engagement opportunities.
After pruning, there are still a large number of patient engagement opportunities that remain. If alert volume were not a concern, prioritization would be unimportant. However, by design, we want to be in a situation where we “cast a wide net” and identify many possible engagement opportunities to avoid patients “slipping by”. Thus, there are often more engagement opportunities identified than coaches can address in a single day. The next critical step is prioritizing the remaining alerts so that the most time-sensitive and useful ones are surfaced today, and that others can be surfaced later. Over the years, we have experimented on the spectrum of prioritizing based completely on rules provided by clinicians, to based solely on machine learning algorithms (with a variety of optimization criteria). Neither of these extremes met coaches’ needs completely. We currently use a hybrid approach that mixes rules and ML techniques, which has performed better than either approach alone. Generally speaking, we give higher priority to:
- Engagement opportunities that are most time-sensitive.
- Patients who have not received a message from a coach recently.
- Patients who began treatment more recently to ensure they are off to a good start.
Once engagement opportunities are ranked by priority, we select the top V – E patients, where V is the volume constraint (to avoid overloading coaches). We then tack on E additional patients, randomly selected from the remaining engagement opportunities. This bit of exploration accelerates continuous learning and avoids local optimums. In other words, by including alerts that don’t adhere strictly to our current prioritization scheme, it’s actually easier to determine what should be prioritized higher, because if we left them out, we would not learn much about them. Prioritization algorithms remain an active area of development as we are always looking to be more efficient without sacrificing quality of care.
4. Aggregate, reformat, and add engagement opportunities to the Alert Queue.
The final steps of the pipeline involve reformatting the alert information in a way that is useful for coaches. First, engagement opportunities are aggregated for each patient and reformatted with some patient context to assist coach action (for example, the dates of most recent biomarker values). Next, we use Celery to send the alert information to RabbitMQ, which powers the Alert Queue visible to coaches in our EHR.
5. Collect feedback on alert relevance.
Years ago, the earliest versions of the alert system did not have a robust feedback mechanism. We relied primarily on qualitative feedback from coaches to distinguish between which alerts were useful, which were not, and which ones to modify. This was good enough to get us started, but became insufficient as the coach team grew. We needed a way to comprehensively collect information on alert relevance to (1) track effectiveness (how is the system performing over time?) and (2) inform updates (how can we make it better?). We also needed the feedback mechanism to be easy for coaches to use and not hinder their workflow. In a collaborative effort, we designed and implemented new buttons (“Took Action” and “No Action Taken”) for the alerts, which have proved extremely valuable. If alert generation were perfect, we’d be identifying the right patients at the right time for the right reason and coaches would take action 100% of the time (and report no patients “slipping by”). In reality, sometimes the alert criteria might not make sense for a given patient’s specific circumstances, or the timing is not quite right and coaches do not take action.

Progress-to-Date
During the first half of 2021, we redoubled our focus on identifying ways to increase the metric of success, the Percent Action Taken (i.e. # “Took Action” / # Total Alerts), and made multiple changes to the system. For example, we modified some engagement opportunity criteria to be more strict where there were too many unuseful alerts. We also adjusted the prioritization algorithm. We made over a dozen of these types of changes during this time, and observed an increase in Percent Action Taken as the alerts increased in relevance. This type of rapid, relentless iteration was made possible by architecting the system with “alert-level” and “system-level” parameters described in the next section.

Five Lessons Learned from Building the Proactive Alert Pipeline
#1 - Importance of Parameterization: While we have ideas from our clinical colleagues on how to define engagement opportunity criteria, there’s often uncertainty on what exactly is most effective. Furthermore, definitions of engagement opportunities often change over time as we continue to optimize other aspects of the Virta Treatment and expand into new populations. To enable flexibility, steps 1-3 above (i.e. engagement opportunity definitions, pruning algorithms, and prioritization algorithms) all have tunable parameters. Parameterization in many areas of the pipeline allows for: (1) exploration & optimization over wider scope of plausible scenarios, and (2) simpler code modifications and more rapid deployment cycle.
#2 - Importance of Collaborating with Clinical Experts when Adjusting Parameters: As described above, we continuously evaluate aggregate data (Percent Action Taken trends & qualitative coach feedback) and selectively remove, modify, or add new engagement opportunities. At some point this may be fully automated, but for now we blend quantitative data with qualitative feedback from coaches prior to enacting changes. Similar to the drivers in autonomous vehicles that are currently under development, while many aspects are completely controlled by AI, for certain types of decisions we want to keep a human in the loop to monitor and make a correction if needed.
#3 - Importance of Experimentation & Iteration: As alluded to above, another key element of success with this system is conducting occasional technical pilots and tests to systematically determine which prompts, processes, and features are working well, and which should be discarded or modified. In a typical experiment, the coach team is divided into different groups that receive alerts generated by different configurations. In this way, we can methodically assess the impact of changes.
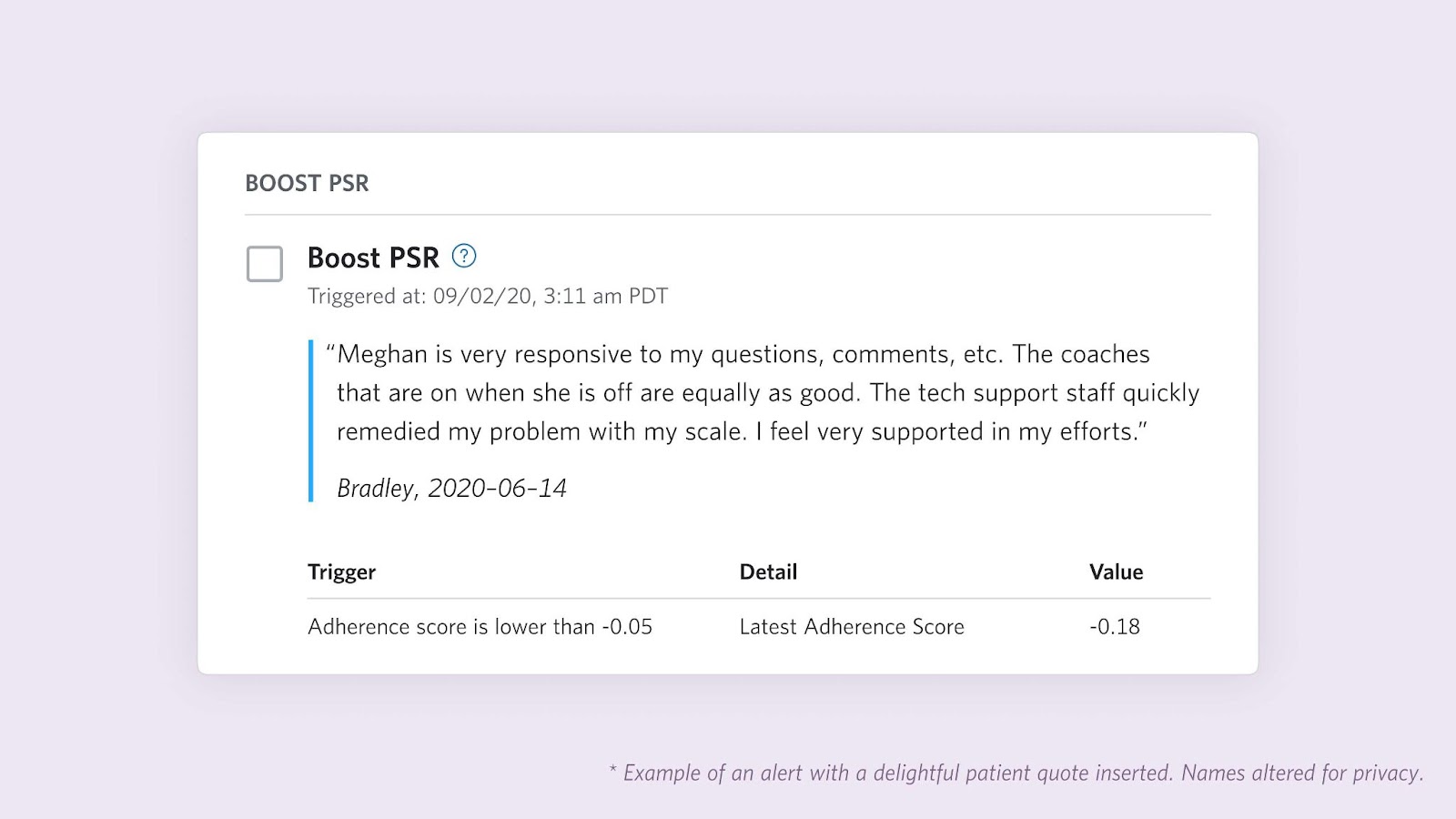
#4 - Importance of Seizing Opportunities to Delight Users: I’ve mostly been describing proactive coach alerts as a mechanism to identify patients who may benefit from coach assistance. While this remains the core purpose, we added other functions to delight users and increase effectiveness. First, we heard from coaches that it would be useful and more energizing (for coaches and patients) to also highlight accomplishments when patients reach certain goals. To this end, we introduced celebrations that notify coaches when patients reach milestones such as reaching an estimated HbA1c below the diabetes threshold or losing 5% of their weight. Second, we also used the alert surface to add some personalized “surprise & delight” for coaches themselves. For example, in partnership with clinical experts and full stack engineers, we added the ability to sporadically insert positive feedback from patient surveys into the coach workflow.
#5 - Integrating AI Products for Greater Impact: Lastly, I’ll highlight that while some alerts are based on explicit rules (e.g. “No Glucose Logs in X Days”), others are a bit more complex and rely on other machine learning algorithms. For example, we have models for predicting dropout and estimating HbA1c (an important blood test for diabetes that requires a lab visit) that are incorporated into specific alerts and help with system-level prioritization. By integrating these different AI products, we get much more out of them than if they were working in isolation.
Conclusion
To conclude, I’ll take a step back and recap four (+2 bonus) larger themes that are important for successfully deploying an AI-driven alerting system for proactive care, which can make healthcare more effective and efficient. They may also translate to other fields, like education, where intervening early can help students achieve their academic goals.
- Cross-functional collaboration is essential to building a functional and useful system.
- Collecting structured feedback on alert relevance as soon as possible is critical to long-term success.
- Building flexibility into the system with parameterization will pay off, since it’s unlikely to be perfect on the first try and even if it were, those parameters will need to change over time.
- Relentless iteration is important as circumstances change.
- Bonus 1: Seize opportunities to delight users.
- Bonus 2: Incorporate other AI products into the alerting system.
This blog is intended for informational purposes only and is not meant to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or other qualified health provider with any questions you may have regarding a medical condition or any advice relating to your health. View full disclaimer
Are you living with type 2 diabetes, prediabetes, or unwanted weight?
